In web development, the backbone of every successful project lies in the efficiency and prowess of its backend. It can be challenging for developers to select the most suitable backend technology.
Among many options, Node.js and Python are widely used server-side technologies, each with its set of pros and cons. The decision to use a particular technology is not only a programmer’s choice, based on his/her own preferences and skills. Often the nature of the project at hand plays a central role in this decision-making process.
Trying to choose between Node.js and Python, developers often find themselves at the crossroads. Opting for one of them can profoundly impact the project’s performance and scalability.
Recognizing the complexity of this decision, our article will cover some differences between Node.js and Python to help you choose which is better for the backend development.
Table of Contents
- Node.js vs Python: Brief Overview
- Node.js vs Python: Detailed Comparison
- Node.js vs Python: Performance and Speed
- Node.js vs Python: Scalability and Concurrency
- Node.js vs Python: Learning Curve
- Node.js vs Python: Community and Ecosystem
- Node.js vs Python: Architecture
- Node.js vs Python: Use Cases and Industry Adoption
- Node.js vs Python: Error Handling
- Node.js vs Python: Pros and Cons
- Node.js vs Python: A Final Comparison
- Summary
Node.js vs Python: Brief Overview
Node.js was initially released in 2009 by Ryan Dahl. At its core, Node.js is a JavaScript runtime built upon the powerful V8 engine. It introduced a groundbreaking concept – the ability to execute JavaScript on the server side, challenging the conventional boundaries of web development.
Node.js was crafted to address the challenges of building scalable and high-performance network applications. Its event-driven, non-blocking I/O model enables developers to create applications that are efficient and responsive in real-time.
Primarily designed for building fast, scalable network applications, Node.js is well-suited for real-time applications such as chat applications, online gaming, and streaming platforms.
On the other side, Python is a versatile, high-level programming language, whose first official release was in 1991. Known for its readability and simplicity, Python supports multiple programming paradigms and has a vast standard library.
Python’s purpose extends beyond the confines of web development. Its ease of use and readability make it an ideal choice for rapid development and prototyping.
Node.js, with its non-blocking approach and emphasis on concurrency, is tailored for applications demanding real-time responsiveness and scalability. On the flip side, Python, with its versatile and readable syntax, caters to a broader range of projects (web development, data science, and beyond).
Read also a detailed comparison of Flutter vs React Native
Node.js vs Python: Detailed Comparison
When it comes to building the backbone of your web project, picking the right technology plays a crucial role. In this comparison, we’re breaking down Node.js vs Python, the heavyweights of web development.
We’re looking at seven essential factors that can make or break your decision:
- Performance and Speed
- Scalability and Concurrency
- Learning Curve
- Community and Ecosystem
- Architecture
- Use Cases and Industry Adoption
- Error Handling
This dive into the nitty-gritty details will help you see the strengths and weaknesses of both Node.js and Python. By the end, you’ll have a clear path to choose the right tech for your project.
Node.js vs Python: Performance and Speed
In the tech world, how fast your web app works is a big deal. So, as we start comparing Node.js vs Python, our first stop is performance and speed.
Node.js
Node.js is characterized by its exceptional speed and efficiency. Built upon the V8 JavaScript runtime, Node.js employs a non-blocking, event-driven architecture. This means it can handle multiple concurrent connections efficiently, making it a powerhouse for real-time applications.
Thanks to its non-blocking approach, it’s perfect for applications that need to update in real-time, like chat apps or online games.
Python
Now, Python isn’t as speedy as Node.js in some situations. Python’s strength lies in its simplicity coupled with a wide range of technical solutions. It may not be the fastest, but it’s really good at getting things done quickly and being readable.
Python also covers a wide range of projects, offering a balance between speed and versatility.
Node.js vs Python: Scalability and Concurrency
Scalability and concurrency form the bedrock of a system’s ability to evolve seamlessly with the growing demands of the digital realm.
Node.js
Node.js, with its non-blocking, event-driven architecture, stands out for its exceptional scalability and concurrency capabilities. Tailored to efficiently handle numerous connections simultaneously, Node.js excels in scenarios where real-time responsiveness and high scalability are paramount.
Its ability to manage a large number of concurrent operations makes it a go-to choice for applications with rapidly expanding user bases or those requiring swift, dynamic updates.
Python
Python, known for its simplicity and versatility, approaches scalability and concurrency with a different yet robust perspective. While it may not match the raw speed and concurrency levels of Node.js, Python compensates with its readability and adaptability.
The Global Interpreter Lock (GIL) in Python can introduce considerations in multi-core environments, impacting its concurrency performance. Nevertheless, Python remains a solid choice for projects prioritizing ease of use, readability, and a diverse range of applications.
Node.js vs Python: Learning Curve
The learning curve in technology adoption is a critical factor that shapes how swiftly and effectively a developer can integrate a new language or framework into their skill set. Understanding the importance of the learning curve is fundamental in making informed decisions about the technologies to choose.
Node.js
Node.js presents a learning curve that can be characterized as moderate to steep, depending on a developer’s background. For those well-versed in JavaScript, the transition to Node.js can be relatively smooth, as the language consistency is maintained between client and server-side.
However, for developers new to JavaScript or those accustomed to synchronous programming, the asynchronous, event-driven paradigm of Node.js may pose a challenge initially.
The need to adapt to non-blocking I/O and embrace callback patterns can introduce complexity. Yet, once this paradigm is grasped, developers often find themselves appreciating the efficiency and performance benefits it brings to the table.
Python
On the other hand, Python is renowned for its gentle learning curve. The language’s readability and simplicity make it particularly welcoming for beginners and those coming from diverse programming backgrounds.
Python’s syntax is clear and straightforward, emphasizing readability and reducing the amount of code needed for tasks. This inherent simplicity accelerates the learning process, enabling developers to quickly grasp the language’s fundamentals and start building applications.
Python’s emphasis on code readability and its extensive standard library contribute to an environment conducive to rapid learning and development.
Ultimately, when considering the learning curve, developers must weigh their existing skill set and project requirements. The decision between Node.js and Python in terms of the learning curve hinges on individual preferences, project needs, and the desired balance between efficiency and ease of adoption.
Node.js vs Python: Community and Ecosystem
An ecosystem ensures that developers have access to a diverse set of tools, enabling them to build a wide array of applications efficiently.
However, for developers, a strong community and a rich ecosystem mean more than just technical support. It signifies a sense of belonging, a network of peers and mentors, and a wealth of resources that accelerate learning and development.
Node.js
Node.js boasts a vibrant and enthusiastic community, driven by its commitment to open-source collaboration. This community actively contributes to the Node.js ecosystem, continuously expanding its horizons.
The Node Package Manager (NPM) serves as a testament to this, hosting a vast repository of packages and libraries for developers. The wealth of available modules simplifies the development process, enabling developers to leverage pre-built solutions and accelerate their projects.
Python
Python, with its extensive and diverse community, stands as one of the most widely adopted programming languages. The Python Software Foundation plays a pivotal role in coordinating community efforts and ensuring the language’s growth.
The Python Package Index (PyPI) serves as a centralized repository for Python packages, providing developers with a treasure trove of tools and libraries.
Python’s community is known for its inclusivity, making it accessible for developers of all levels.
Node.js vs Python: Architecture
Architecture of a technology determines how applications are structured, how data flows, and how developers interact with the underlying framework.
For developers, the architectural differences between Node.js and Python dictate the development approach and also impact factors such as performance, scalability, and ease of maintenance. The choice between the two architectures rests on the project’s specific demands and the developer’s preferences in terms of programming style and application requirements.
Node.js
Node.js introduces an event-driven, non-blocking architecture, a departure from traditional synchronous models. At its core is the V8 JavaScript engine, renowned for its speed and efficiency.
The event loop in Node.js enables asynchronous handling of tasks, making it well-suited for scenarios requiring real-time responses and scalable network applications. Its single-threaded, event-driven design allows it to handle multiple concurrent connections seamlessly.
Python
Python, in contrast, adopts a multi-paradigm, interpreted language approach. Its architecture emphasizes readability and simplicity, making it a versatile choice for various applications.
Python follows a synchronous, multi-threaded or multi-process model, with the Global Interpreter Lock (GIL) impacting concurrency in certain scenarios.
However, Python’s architecture allows developers to leverage multi-threading or multiprocessing for parallel execution.
Node.js vs Python: Use Cases and Industry Adoption
The practical applications and use cases define the versatility and suitability of a technology or framework. As we compare Node.js vs Python, we’ll spotlight their distinctive use cases.
Node.js
Node.js has gained significant traction in industries that require real-time applications and scalable network solutions. It is commonly used in areas such as:
- Fintech
- Gaming
- Streaming Services
- Chat Applications
Its ability to handle a large number of concurrent connections makes it suitable for scenarios where responsiveness and scalability are critical. The Node.js community actively contributes to the development of libraries and frameworks that cater to these specialized domains.
Python
Python’s versatility has led to widespread adoption across various industries. It is prominently used in:
- Web Development
- Data Science
- Machine Learning
- Artificial Intelligence
- Scientific Computing
Python’s readability and extensive standard library make it applicable to diverse use cases. The Django framework is popular for building robust web applications, while Python’s data science libraries like NumPy and pandas contribute to its dominance in the data analytics field.
Node.js vs Python: Error Handling
Node.js and Python, with their unique strengths, provide developers with the tools needed to navigate and troubleshoot effectively.
While Node.js excels in handling the intricacies of asynchronous operations, Python emphasizes readability and simplicity in debugging, catering to diverse developer preferences and project requirements.
Node.js
Node.js introduces unique challenges for debugging. The built-in Node.js Debugger and tools like ndb cater specifically to the asynchronous nature, offering developers the ability to navigate through asynchronous code seamlessly.
Moreover, Node.js relies on callbacks and event emitters for error handling. The ‘error’ event is a central component, allowing developers to capture and manage errors in asynchronous operations.
Python
Python provides a built-in debugger module, PDB (Python Debugger), offering developers a powerful toolset for stepping through code, inspecting variables, and tracing execution. The PDB simplifies the process of identifying and resolving issues during development, contributing to Python’s reputation for readability and ease of debugging.
Additionally, Python places a strong emphasis on exception handling, enabling developers to create resilient applications. The try-except blocks in Python allow developers to gracefully handle specific errors, preventing application crashes.
Python also includes a robust logging module, allowing developers to record diagnostic messages and facilitate effective debugging.
Node.js vs Python: Pros and Cons
Node.js and Python, both powerful in their own right, have their own set of advantages and considerations. Understanding pros and cons helps developers make informed decisions based on their project requirements and priorities.
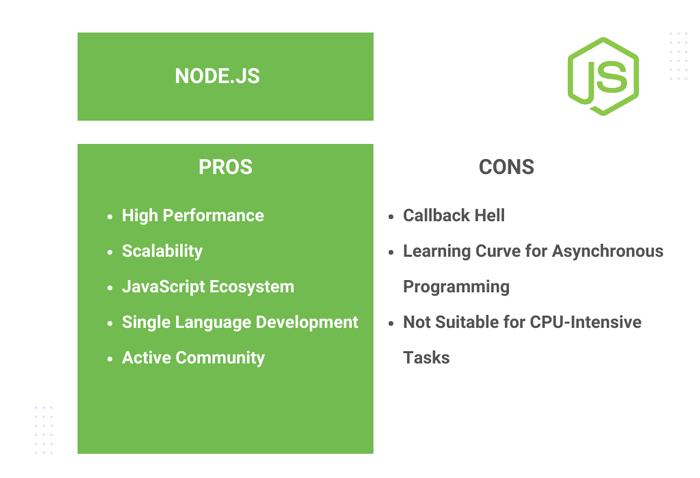
Node.js Pros
- High Performance: Utilizes a non-blocking and event-driven architecture for efficient handling of concurrent connections, making it well-suited for real-time applications.
- Scalability: Excellent scalability due to its asynchronous nature, making it ideal for projects with a large number of concurrent users.
- JavaScript Ecosystem: Leverages the vast and vibrant JavaScript ecosystem, with a multitude of libraries and frameworks available through npm.
- Single Language Development: Enables full-stack JavaScript development, allowing developers to use the same language (JavaScript) for both frontend and backend development.
- Active Community: Node.js has a large and active community, contributing to the continuous improvement and evolution of the technology.
Node.js Cons
- Callback Hell: Asynchronous programming can lead to callback hell or the “pyramid of doom,” where nested callbacks become hard to manage.
- Learning Curve for Asynchronous Programming: Developers new to asynchronous programming may face a learning curve in grasping the intricacies of event-driven development.
- Not Suitable for CPU-Intensive Tasks: May not be the best choice for CPU-intensive tasks due to its single-threaded nature.
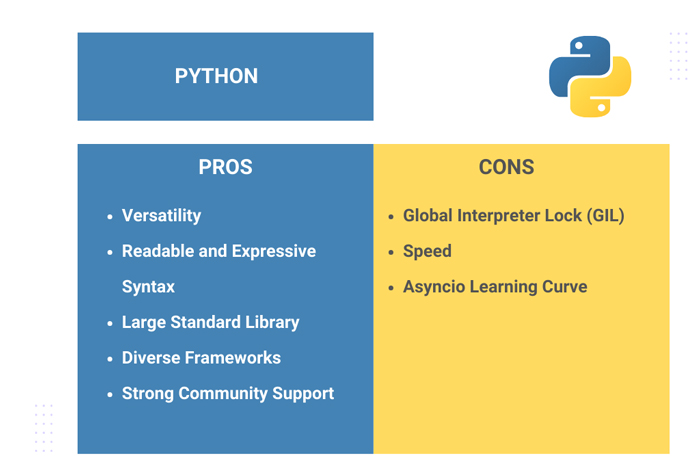
Python Pros
- Versatility: A versatile language used in a wide range of applications, including web development, data science, machine learning, automation, and scientific computing.
- Readable and Expressive Syntax: Emphasizes readability and simplicity, with a clear and expressive syntax that facilitates easy understanding of code.
- Large Standard Library: Python offers a comprehensive standard library, providing modules and packages for various functionalities without additional installations.
- Diverse Frameworks: Supports multiple frameworks such as Django and Flask for web development, providing flexibility and choice.
- Strong Community Support: Python’s strong and supportive community contributes to an extensive array of third-party libraries and resources.
Python Cons
- Global Interpreter Lock (GIL): The Global Interpreter Lock can limit the effectiveness of multi-threading in CPU-bound tasks.
- Speed: While versatile, Python may not be as performant as some languages in specific scenarios, particularly in high-performance computing.
- Asyncio Learning Curve: Asynchronous programming in Python, using libraries like asyncio, may pose a learning curve for developers accustomed to synchronous paradigms.
Node.js vs Python: A Final Comparison
Choosing the right programming language for your project is a pivotal decision that significantly influences its success. Node.js and Python each have their own unique strengths.
This summary table aims to equip developers with final insights to make an informed choice tailored to their project requirements.
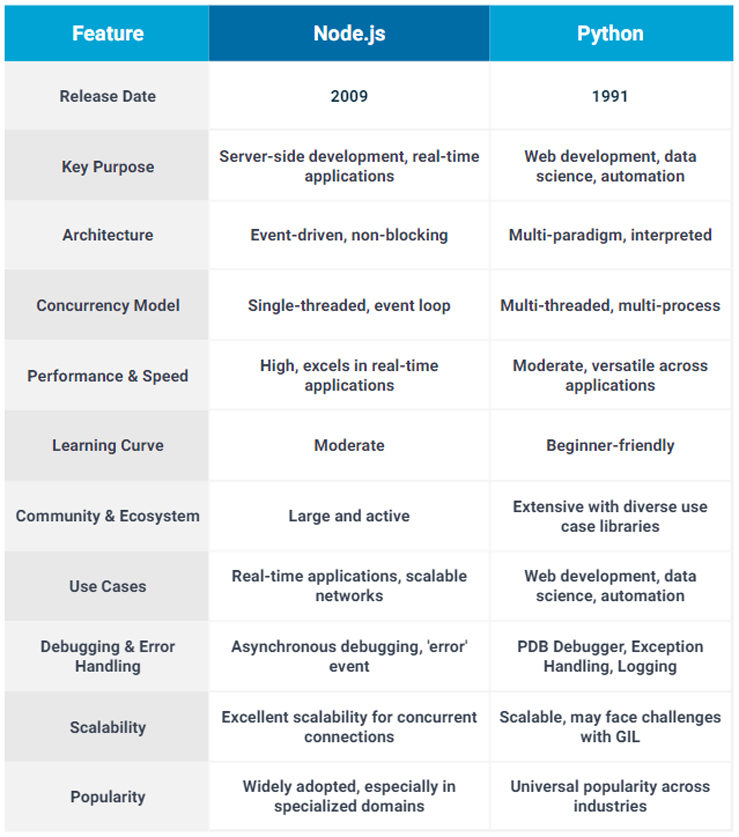
Note: This table provides a high-level overview, and the choice between Node.js vs Python should be based on specific project requirements, development preferences, and the nature of the application.
Summary
In conclusion, both Node.js and Python stand as powerful technologies, each with its unique strengths and weaknesses.
Node.js offers high performance and scalability, and excels in scenarios demanding swift response times and handling numerous concurrent connections. Also Node.js provides a single-language development environment, allowing developers to seamlessly navigate both frontend and backend domains. However, it comes with considerations such as the potential for callback hell and a learning curve for asynchronous programming.
On the other hand, Python’s readability and expressive syntax contribute to its popularity in web development, data science, machine learning, and beyond. With a large standard library and robust frameworks like Django and Flask, Python provides developers with a wealth of tools. Nevertheless, the Global Interpreter Lock (GIL) poses challenges in CPU-bound tasks, and the learning curve for asynchronous programming may require adaptation.
Ultimately, the choice between Node.js and Python hinges on project needs. For real-time applications and scalable network solutions, Node.js shines. Meanwhile, Python’s adaptability makes it a go-to for web development, data science, and automation.
Developers must weigh the demands of their projects, team expertise, and the nature of the application to determine the technology that aligns most closely with their objectives. Understanding the nuances of Node.js and Python is the compass that helps choose the best approach for building the backend of your application.